AFM Filières en mode batch¶
Le mode batch est d’une part utilisé pour le développement et le débogage mais il permet aussi d’accéder à des fonctionnalités avancés non disponibles dans WebApp.
Format du fichier Excel d’entrée¶
Les Onglets¶

Le fichier excel d’entrée est composé de six onglets répartis en trois groupes:
Description de la structure de la filiére d’approvisionnement : onglets produits, secteurs, flux pouvant exister.
Les données disponibles avec leurs incertitudes : onglet données. En entrée ces données sont incomplétes et incohérentes et doivent être réconciliées.
Des informations supplémentaires pour la réconciliation : onglets min max et contraintes
Onglets « produits » et « secteurs »¶
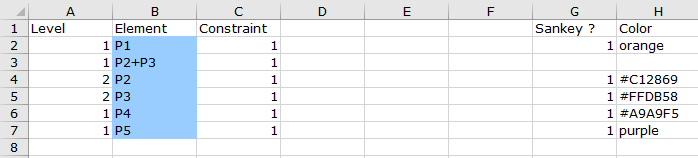
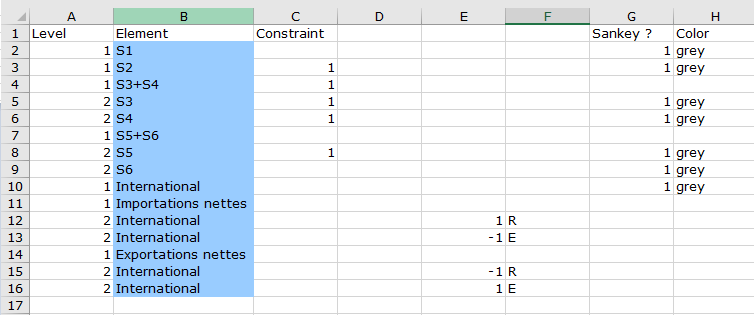
Les formats de ces deux onglets sont identiques.
La première colonne Level décrit le nouveau d’agrégation. Pour une ligne avec niveau d’agrégation donné n, les lignes dessous avec le niveau n+1 correspondent aux produits désagrégés. Par exemple la ligne 3 avec le produit P2+P3 contient les produits P2 et P3 des lignes 4 et 5.
La seconde colonne Element contient les noms des produits ou secteurs.
La troisiéme colonne Constraint détermine respectivement pour les produits (ou secteurs) si la contrainte somme des lignes (ou colonne ) dans la table emploi est égale à la somme des lignes (ou colonne) dans la table ressource. Si la valeur est un cette contrainte est activée. Les cas ou la contraite est désactivée sont soit quand le produit (ou secteur) est disponible sans secteurs productifs (ou sans production de produits) correspondants ou au contraire sans secteurs consommateurs (ou sans produits entrants dans le processus de production).
Les colonnes Sankey ? et Color spécifient si les produits ou secteurs doivent être représenté dans le diagramme de sankey ( typiquement pour différents niveaux d’aggrégation on ne veut pas les représenter en même temps). et avec quelles couleurs ils doivent être dessinés. Pour leur utilisation dans l’application Diagrammes de sankey voir Génération automatique de diagramme
Les colonnes E et F en conjonction avec la colonne Level servent à recombiner avec des poids dans la colonne E (poids 1 et -1 dans l’exemple) des produits (ou secteurs) provenant des deux tables emplois (E dans la colonne F) ou ressources ( R dans la colonne F). Dans l’exemple
Importations nettes = International (Table Ressource) - International (Table Emploi)
Onglet « flux pouvant exister »¶
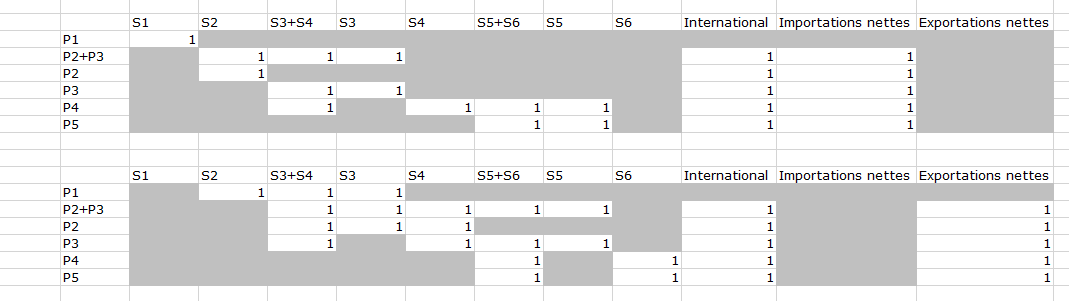
Cet Onglet contient les deux tables ressource (en haut) et emploi représentent les flux pouvant exister. Rappelons que dans la table ressource les secteurs en colonne sont producteurs des produits en ligne et dans la table emploi les secteurs sont consommateurs des produits en ligne.
Les cases en grisés sont des flux qui ne peuvent pas exister. Les flux avec 1 sont ceux qui peuvent exister. Attention qu’un flux qui peut exister peut in fine avoir une valeur nulle en sortie de réconciliation, à bien distinguer des flux qui ne peuvent pas exister dont on sait que le flux est nul avant de réconcilier.
Onglet « données »¶
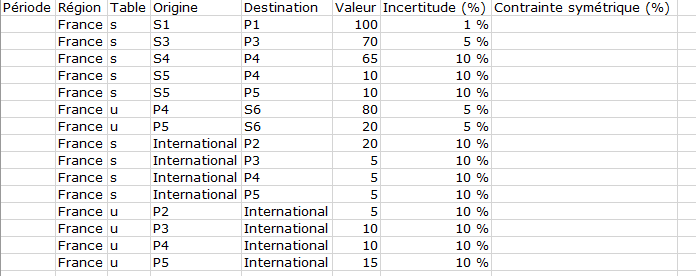
L’onglet présenté ci-dessus est la version simple et minimale de l’onglet données.
La colonne A Période est pour l’instant uniquement informative, elle peut être vide comme ici ou contenir quelque chose comme « moy. 2009-2015 ».
La colonne B Région contient l’information sur la région. Dans l’exemple montré où on ne fait pas de réconciliation géographique il contient une seul valeur « France ».
La colonne C table spécifie la table pour laquelle on spécifie la donnée : Ressource (s pour supply) ou Emploi (u pour use).
Les colonnes D origin et D destination spécifient l’origine et destination du flux pris dans la liste des produits et secteurs spécifiés dans les deux premiers onglets. Pour être cohérent si Table est « s » l’origine est un secteur et la destination un produit et vice-versa si Table est « u »
La colonne F Valeur contient la valeur de la donnée dans l’unité de l’étude choisie
La colonne G Incertitude (%) contient l’incertitude sur la donnée en pourcentage
La colonne H Contrainte symétrique sert à spécifier les bornes min et max en pourcentage de la valeur (dans l’onglet min max c’est en valeur absolu)
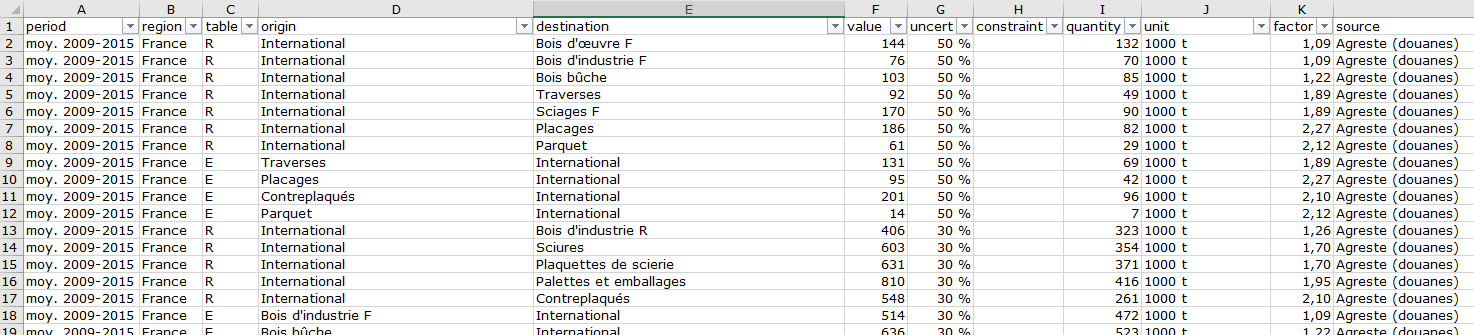

Les deux onglets ci-dessus issues d’études sur la filière bois et la filière lait présentent la forme compléte de l’onglet.
La colonne I quantity est la valeur de la donnée dans son unité d”origine. Elle doit être convertit (en utilisant K factor) dans l’unité de l’étude pour remplir la colonne F Valeur qui sera la valeur numérique utilisée dans la réconciliation.
La colonne J unit est l’unité d’origine des données.
La colonne K factor est utilisée pour convertir I quantity en F Valeur.
La colonne L source est informative. Elle sert en général à fixer la valeur d’incertitude en G Incertitude (%).
Onglet « min max »¶
Onglet « contraintes »¶
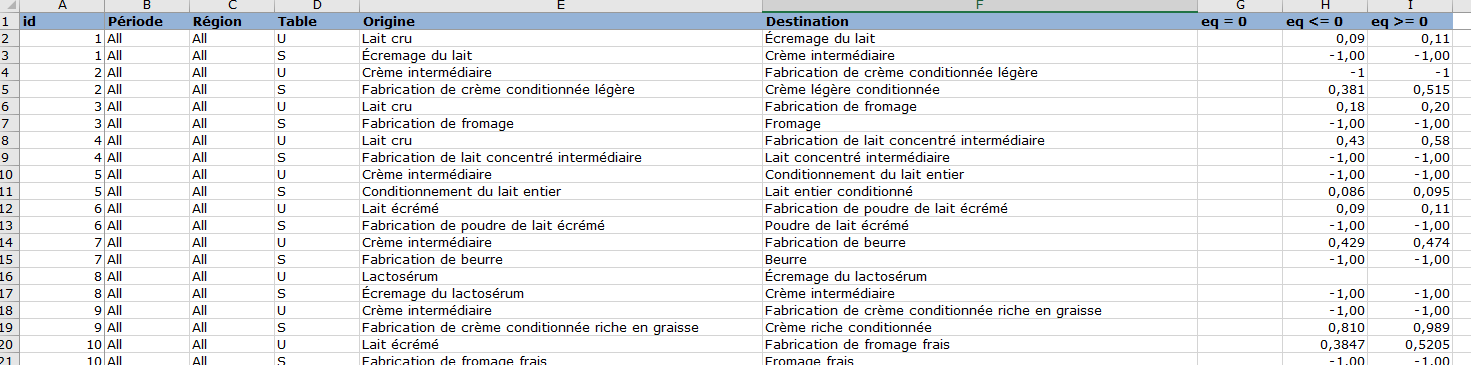
Cette onglet permet d’ajouter des contraintes additionnnelles en plus des contraintes sur lignes et colonnes, les contraintes de minimum et maximum et les contraintes d’aggrégation. Le format est le suivant:
La colonne A id est le numero de la contrainte.
La colonne B Période est la période concerné
La colonne B Region est la région
La trois colonnes suivantes D Table, E origine et F Destination spécifie la variable sur laquelle porte la contrainte.
Les trois colonnes suivantes spécifient le type de contrainte: égalité, inférieur ou égal, supérieur ou égal. Pour le même id plusieurs contraintes peuvent être spécifiés (en général inférieur ou égal avec supérieur ou égal. )
Ainsi pour la contrainte avec id=1 si on appelle:
Flux1 le flux de consommation de lait cru par le secteur Ecrémage du lait
Flux2 le flux de production de Créme intermédiaire par le même secteur
On a les deux contraintes
et
Format du fichier Excel de sortie¶
Les nouveaux onglets de sortie¶

Le fichier de sortie est composé des onglets d’entrée plus sept nouveaux onglets. Les onglets de sorties stricto sensu sont result list full et result ter display, le premier étant celui qui est utilisé par l’appplication de diagramme de sankey quand on charge le fichier dans cette application (voir Génération automatique de diagramme).
Les autres onglets sont intermédiaires et peuvent être utilisés pour une analyse approfondi.
Les deux premiers onglets result liste et Ai contiennent les résultats pour les variables qui sont intervenus dans la réconciliation et exclue donc les variables qui sont de simples combinaisons linéaires des autres variables.
L’onglet result liste¶
L’onglet result liste reprend l’onglet données et le compléte par les colonnes suivantes
H sigma in et I sigma in % qui reprennent les incertitudes en entrée exprimés en valeur absolu et en pourcentage.
J min in et K max in qui reprennent les valeurs minimum et maximum calculées à partir de l’onglet min max ou la colonne contrainte dans l’onglée données.
L valeur out est la valeur réconcilié du flux en général différent mais proche de la valeur dans G valeur in
M nb_sigmas est la différence entre la valeur d’entrée et réconciliée en terme de sigma (H sigma in)
Les colonnes suivantes sont utilisés pour l’analyse ou le debogage
N Ai
O free min Ai
P free max Ai
Q rref python1 classif